
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- red-black tree
- sort
- template
- deletion
- qsort
- 5397
- data_structure
- class_template
- 자료구조
- 예제
- 알고리즘
- Critical_Path_Analysis
- singly Linked List
- function_template
- 백준
- c++
- 13305
- Biconnected_Component
- Heap
- Articulation_Point
- Algorithm
- Pair
- sstream
- 문법
- 구현
- list
- '0'
- STL
- connected_component
- 총정리
- Today
- Total
- Today
- Total
- 방명록
어제의 나보다 성장한 오늘의 나
[C++] Trie 총정리 / 구현 / 응용 ( Insert , Find ) 본문
Trie
◎ 문자열들을 저장하기 위해 사용되는 트리 자료구조
◎ 각 노드가 26개의 자식 포인터를 가짐
◎ 빠른 문자열 탐색 속도
1) 작동 원리
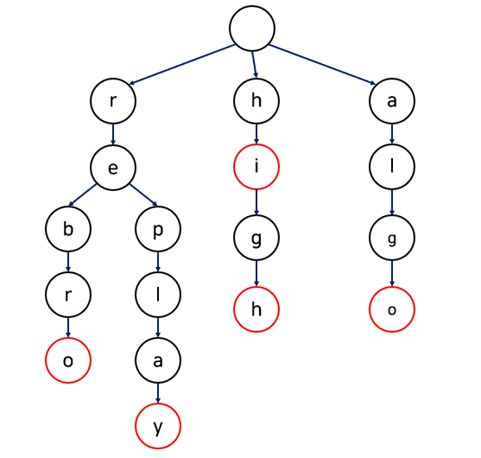
문자열들이 저장되어 있는 Trie 의 모습이다.
저장된 문자열
[ rebro , replay , hi , high , algo ]
문자열 한 글자씩 노드에 저장 해두었고 끝나는 지점을 bool finish 변수를 통해 표시 해두었다.
( 빨간색 동그라미 부분 -> finish 변수 true)
문자열 탐색하는 과정
문자열 "High" 를 찾는 다고 가정을 해보겠다.
제일 꼭대기에 있는 Root 노드 에서 High의 첫 글자인 H를 먼저 찾는다.
자식 노드 들 중 H 노드가 존재하기에 H 노드로 이동 할 수 있다.
이동한 뒤 두 번째 글자인 I 를 찾는다.
I 노드 도 있고 그 다음 G , H 노드들도 존재 하기 때문에 H노드 까지 이동할 수 있다.
H 가 마지막 글자이기 때문에 H 노드에서 finish 변수가 true 인지 체크 한다.
H 노드의 finish가 true( 빨간색 동그라미 )이므로 저장된 문자열이 맞다. ( 탐색 완료 )
요약
Root 노드 시작
-> H 노드 이동
-> I노드 이동
-> G노드 이동
-> H노드 이동
-> finish 체크 ( True , 빨간색 동그라미 )
-> 탐색 성공 ! 문자열 존재
존재 하지 않는 문자열들 Case 2 가지
Case 1) 노드 존재 X
위의 Trie에서 “”HILL” 문자열을 찾는다고 가정해보자
Root 노드
-> H 노드 이동
-> I 노드 이동
-> L 노드 존재 X
-> 탐색 실패!
Case 2) 노드 존재 , finish가 false
위의 Trie에서 “HIG” 문자열을 찾는다고 가정해보자
Root 노드
-> H 노드 이동
-> I 노드 이동
-> G 노드 이동
-> finish 체크 ( False, 검정색 동그라미 )
-> 탐색 실패 !
2) Trie 장점 / 단점
장점
문자열 탐색이 굉장히 빠름
탐색의 속도가 O( log n ) 의 시간 복잡도를 가진 ‘이진 탐색 트리’ ( Binary Search Tree ) 를 통해 문자열을 탐색하면 O ( 문자열의 길이 * log n ) 만큼의 시간복잡도가 걸림
Trie의 경우 모든 문자열을 O ( log n ) 로 탐색이 가능 하다.
단점
메모리를 많이 사용함
알파벳은 총 26개이므로 , 문자열을 표현하는 각 노드가 26개의 자식 노드 포인터를 가진다.
포인터의 크기는 32 비트 / 64 비트 기준 각각 4bytes / 8bytes 이다.
64 비트 기준으로 포인터의 메모리는
8 bytes * 26개 * 노드의 갯수 ( 문자열의 길이 * 총 문자열의 갯수 )
메모리의 사용량이 많이 든다. 적시적소에 잘 사용하여 단점을 줄이고 장점을 활용하자!!
3) 구현
필자는 C++로 구현을 하였다.
◎ Node Struct
struct node{
bool finish ;
node* next[ALPHA];
}
각 노드는 26개의 노드 포인터와 finish 여부를 변수로 가진다.
◎ Insert
텅 빈 Trie에 문자열들을 저장해주는 함수
void insert(const char* key){
insert(key , root);
}
void insert(const char* key, node* next[]){
int index = *key -'A';
if(!next[index]) next[index] = new node();
if(*(key + 1) == '\0'){
next[index]->finish = true;
return;
}
insert( key+1 , next[index]->next);
}
문자열 key를 매개 변수로 받아서 key의 문자를 따라 하나씩 이동 해가며 그에 해당하는 노드를 만들어 주는 함수이다. 이미 노드가 존재한다면 만들지 않는다.
이동할 때는 recursion을 이용한다.
문자의 끝에 도달했다면 finish를 true로 바꾸어 준다. ( Finish Defalut가 false 임 )
◎ Find
문자열이 존재하는 지 찾아 주는 함수
bool find(const char* key , node* next[]){
int index = *key - 'A';
if(!next[index]) return false;
if(*(key+1)=='\0'){
if(next[index]->finish) return true;
else return false;
}
return find(key+1 , next[index]->next);
}
bool find(const char* key){
return find(key, root);
}
Insert와 코드가 비슷하다.
찾고자 하는 문자열 key를 하나씩 읽어가면서 노드를 이동해 간다.
이동하려는 노드가 없다면 false를 return
끝까지 도달했으나 finish가 false라면 마찬가지로 false를 return한다.
O(Log n) 의 시간 복잡도로 굉장히 빠르게 탐색 가능하다.
Trie를 응용하여 관련 검색 엔진을 만들어 보았다.
관련 검색 엔진은 네이버, 구글 등 대부분의 플랫폼에서 사용한다.
수많은 검색어들을 Trie를 이용하여 빠르게 탐색 한다면 관련 문자열도 빠르게 찾을 수 있다.
코드는 github에 올려두었다.
Github 주소
GitHub - ohinhyuk/MCNL-Study: for Study
for Study. Contribute to ohinhyuk/MCNL-Study development by creating an account on GitHub.
github.com
'c++ > data_structure_구현' 카테고리의 다른 글
| [C++][자료 구조] Map STL 구현 ( RbTree , Template ,Iterator , Operator overloading ) (0) | 2022.07.23 |
|---|---|
| [c++][자료구조] Complete Binary Tree (완전 이진 트리) 구현 및 응용 함수들 (4) | 2022.02.21 |
| [c++][자료구조] Double Linked List(더블 링크드 리스트) 구현 / List STL (2) | 2022.02.18 |
| [C++] Singly Linked List(싱글 링크드 리스트) 구현 (0) | 2022.02.12 |
| [c++][자료구조] heap 구현 / STL / Priority Queue 총 정리 (0) | 2022.02.12 |
